
Our last blog post explored graph-based abstractions for composing lightweight syntactic code transformations and summarized the key research results in our PLDI 2024 paper, “A Lightweight Polyglot Code Transformation Language”. In this post, we turn to practical considerations: How do we efficiently scale the execution of graph-based rewrite rules to handle large, industrial-scale codebases? And just how performant can we make it compared to existing tooling?
Let’s start with a brief recap of Rule Graphs and an example before covering execution and optimization.
Rule Graphs
A Rule Graph is a directed graph where nodes represent rules that match and rewrite code, edges represent nodes that should evaluate next on a match, and edge labels represent the scope in which the destination node should be evaluated. Rules can capture fragments of matched code into capture variables that propagate along edges. Rules can also have free variables that bind to the captured values that propagate into the rule during rule evaluation.
Example
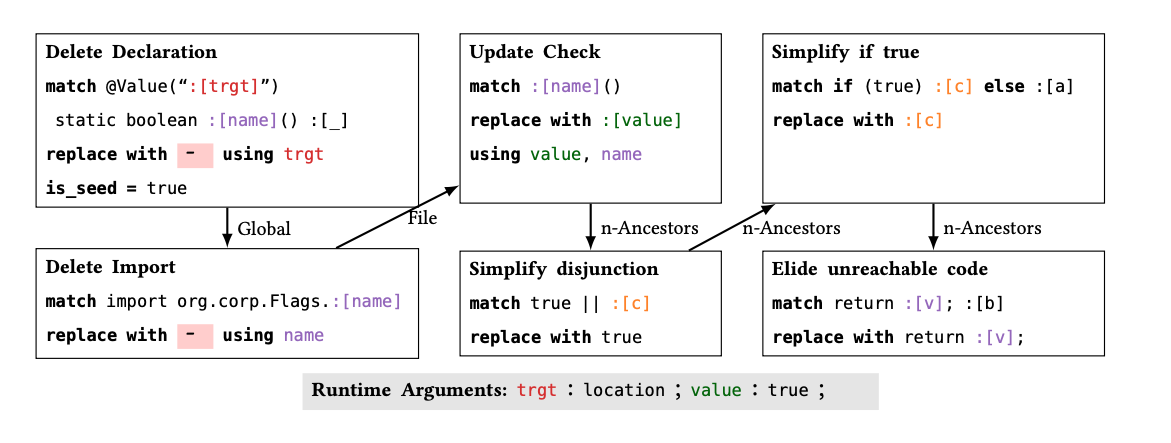
The following rule graph implements a refactor in Java and Kotlin that removes a method matching a given @Value annotation, replaces all existing calls to it with true, and then simplifies the resulting code:
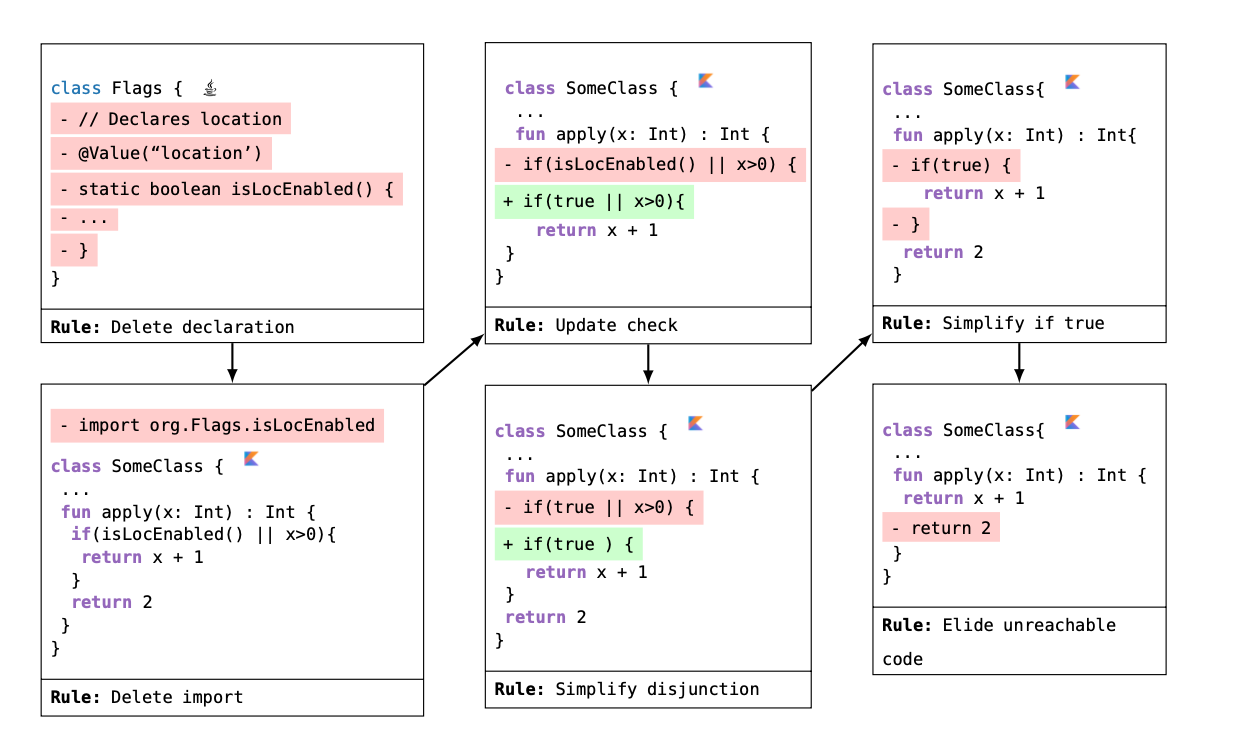
Applied to a concrete example, the above rule graph performs the following code edits:
Rule Graph Execution
The heart of executing Rule Graphs is a graph traversal that starts by matching root nodes across all files. Each file that matches a root node rule kicks-off a depth-first traversal within that file. When a rule successfully matches, its successor nodes are pushed onto a stack.
Capture variables are propagated along edges using a symbol table that maps variables to values. A successful match updates the symbol table with new bindings, and before a rule is evaluated, its free variables are substituted with values looked up in the symbol table.
Edge scopes resolve within the current file relative to the currently matched part of the Abstract Syntax Tree (AST). For example, a Class scope is resolved by traversing up the AST to the innermost enclosing class and passing that AST pointer to the successor node.
Edges with Global scope are special because they don’t resolve within the current file. Instead they are treated like dynamically-encountered root nodes and added to a queue for later traversal.
Static Rule Graph Validation
A number of static validation steps on the Rule Graph help avoid errors during Rule Graph execution. These steps happen at build time for static rules that are compiled into the PolyglotPiranha executable binary and at runtime for dynamic rules that are loaded or created at runtime. The first set of validations make sure that match and replace code fragments are syntactically valid by compiling all node rules. This catches syntax errors in the match and replace rules. The second set of validations make sure that all nodes in the graph are reachable from root nodes. This ensures there are no unreachable nodes in the Rule Graph.
The final set of validations check the integrity of capture variables. A data flow analysis validates that all paths leading to a rule have bound values for all the free variables referenced in the rule. This ensures that the symbol table will resolve all free variables lookups successfully at runtime. Each rule is aso checked for conflicting variable captures, ensuring that a capture variable is defined only once in a node.
Performance Optimizations
PolyglotPiranha includes a number of performance optimizations that allow it to scale to enormous code bases. The first set of optimizations reduce the time spent parsing code. When considering a root node or successor node of a global edge, a fast textual grep filters out files that definitely won’t match these nodes’ rules. This avoids the overhead of parsing and creating ASTs for all files. In addition, when traversing the rule graph, we order the successor nodes so that we edit from inner to outermost scope. This simple heuristic reduces the amount of incremental re-parsing.
The second set of optimizations parallelize execution across files, allowing it to scale up on multiple cores and scale out on a distributed cluster. The outermost execution loop can apply the Rule Graph across multiple files in parallel. This allows execution to take advantage of hardware parallelism across both multiple processor sockets and cores on a single machine, and multiple machines on a cluster.
How well does PolyglotPiranha work in Practice?
At Uber, we used PolyglotPiranha to automatically refactor code across Java (7.5M LoC), Kotlin (2.5M LoC), and Swift (7.5M LoC), across 3 different automated refactorings. Over the course of 6 months, PolyglotPiranha produced nearly 5000 PRs automatically, deleting over 200k LoC.
At Gitar, we strongly believe that our new abstraction, graph-based rewrite engine, and the scalable large-scale code refactoring ecosystem can pave the way for a future of seamless automated code maintenance in large codebases, and vastly increase developer productivity.
Connect with us in slack to learn more about this product!